Raft
1. Raft 算法是怎样的?
1.1 选举
Raft 算法是通过 投票机制,以 少数服从多数 的形式,进行主节点的选举。
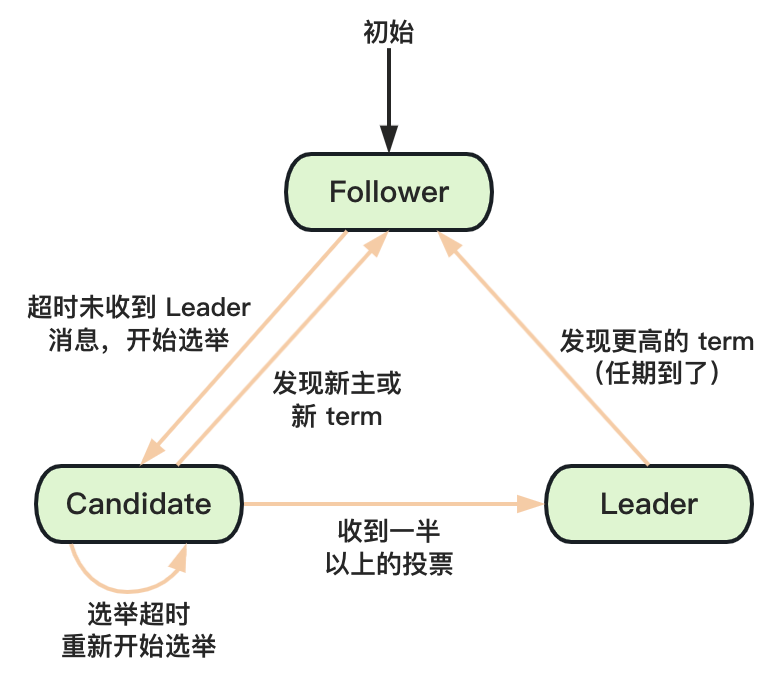
在 Raft 算法中,节点有三种角色:
- Leader:主节点,负责协调和管理其他节点。Leader 节点有一个任期(term),到了就需要重新进行选举(主节点出现故障也会进行重选);
- Candidate:候选者,每个节点都有可以成为 Candidate,Candidate 有机会被选为 Leader;
- Follower:Leader 的跟随者,不可发起选举。
选举过程如下:
- 初始时,所有节点都是 Follower,直到开始选主时,才变为 Candidate,向其他节点发送选举请求;
- 其他节点根据接受到请求的前后进行投票,每轮选举只能投一次票;
- 若发起选举的节点票数过半,则可成为 Leader,接着其他节点都变为 Follower,Leader 会与 Follower 定期发送心跳包以保持联系;
- Leader 任期(term)到后会变为 Follower,开始进入新一轮的选举。
可以发现,Raft 算法在正常工作期间只有 Leader 和 Followers,Candidate 只有在选举时才出现。
Raft 算法将时间分为一段一段的任期(term),每一段 term 的开始都是选举阶段,以选举是否成功来决定是否继续该 term:
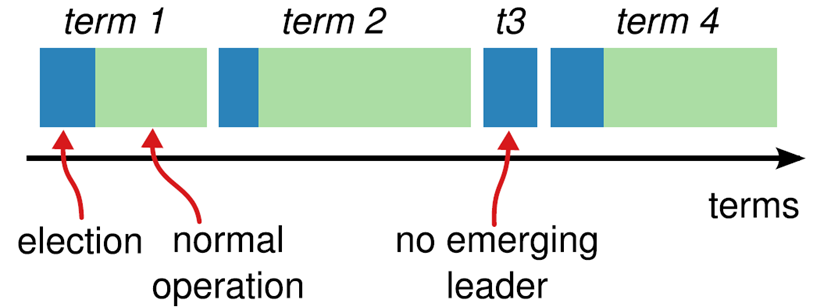
节点角色间的转变关系如下:
在选举出 Leader 后,它会用日志复制 RPC 与 Folllower 进行数据同步和心跳检测。
1.2 日志复制
在 Raft 算法中,副本数据是以日志的形式存在的,Leader 在接受到客户端的写请求后,会以日志的形式同步数据,所以就涉及到日志的复制和提交。
日志是由日志项组成,日志项其实就是一种数据格式,它包括:
- 索引值 Log Index:日志项对应的索引值,连续、单调递增;
- 任期编号 Term:创建该日志的 Leader 的任期编号;
- 指令:客户端发起请求操作的数据。
在复制日志时,Leader 会先通过日志复制 RPC 消息,将日志复制到其他 Follower 上,如果接收到大多数的 “复制成功” 的响应,就会将日志项提交到它的状态机,Leader 就可以返回成功信息给客户端了,否则返回失败消息。
在 Raft 中,状态机是一个抽象的概念,它用来表示分布式系统中要维护的状态,状态机的实现可以有多种,比如数据库、内存、文件等。每个节点都有一个自己的状态机,当日志项成功应用到状态机上时,状态机就会相应的改变,从而使节点间的状态保持一致。
可以发现,Leader 只管自己的状态机,并不会通知 Follower 去提交,Follower 需要自己去提交,如果在接收到 Leader 节点的心跳信息时发现日志提交不一致,则会以 Leader 的日志为准来提交。
如果出现服务器宕机导致日志不一致,Leader 会强制 Follower 直接复制自己的日志项来同步不一致的日志:
- Leader 会先通过日志复制 RPC 找到 Follower 与自己相同日志项的最大索引值(前面日志都一致),然后 直接将后面不一致的日志用 Leader 的覆盖。
对每个日志不一致的 Follower 都需要进行上述的同步。
2. Raft 算法缺点
从上面的选举过程可以看出,Raft 虽然稳定性比较好,只有当票数过半时才会切主,不会因为主节点假死而导致频繁切主。
但是,节点间的通信量较大,每个节点都需要与其他节点进行通信,当节点数量过多时,会耗费大量的网络通信成本,而且选举也会变得比较耗时。